
Ode to the PDF: Complex, Elegant, Sometimes Risky, but Absolutely Necessary

PDF (Portable Document Format) files are integral to business operations; recognized for their convenience and compatibility across countless platforms. And according to a report by the PDF Association, they rank as the third most common file type online, widely utilized in every business sector, from academia to government to corporate enterprises.
However, with this widespread adoption comes a significant concern: the inherent complexity of PDF files introduces heightened security risks. That’s right: we said the inherent complexity of PDF files, which you’ve probably never thought of before – and some of you may even be doubting right now. But think about it: PDFs are the complex utility player of the document world. With a PDF you can embed a massive amount of other objects and elements: links, images, videos, even other PDFs, layered and layered and embedded and embedded in a cascading swirl of business documentation.
The intricacies that enable PDFs to embed rich content, such as complex JPEG images or other media, also make them a potential hotbed for hidden threats. A complex document allows for many structural variations and becomes a breeding ground for vulnerabilities in the code that reads the file. Malicious actors can exploit these vulnerabilities, embedding threats that automatically launch as soon as users open the file.
In this blog, we explore the anatomy of a PDF file to discover the various ways hidden threats can be embedded and discuss how to neutralize them.
Peeling Back the Layers: The Complex Anatomy of a PDF
A PDF file is a multi-layered, intricate structure that encapsulates rich document content. At a high level, a PDF is composed of objects, each of which can be a piece of data, such as text, images, or interactive elements. These objects are typically defined using a combination of operators and operands stored in a table that maps out the locations of objects within a file for quick access. Using a complex set of catalogs and data streams to embed complex content such as images and fonts, PDFs ensure a consistent appearance and functionality, regardless of the device or software used to view it.

Alt Text: Basic Structure of a PDF File
Reference: ISO specifications for a PDF
Starting the File
A PDF header is an essential component of a PDF file that signifies the beginning of the file and specifies the version of the PDF specification to which the file conforms. It’s a simple, readable string at the very start of the file, ensuring that software can quickly identify the file type and version. Typically, the header begins with the characters “%PDF–” followed by a version number, such as “1.7”, indicating that the file complies with version 1.7 of the PDF specification. Additionally, the header often includes a second line containing a series of binary characters. While this might appear arbitrary to the human eye, it serves a specific purpose: it indicates to software that the file may contain binary data, ensuring that it is processed correctly, even if it includes complex elements like images or embedded fonts.
Understanding the Body
The body of a PDF file is its core, containing the bulk of the data that represents the document’s content. The body stores visible elements such as text, fonts, and images along with their meta-data. Each body component breaks down into a series of objects containing a unique identification number to reference later. These objects are complex as they may include the data directly or a reference to other objects to form a rich interconnected structure, defining the layout and content of the document.
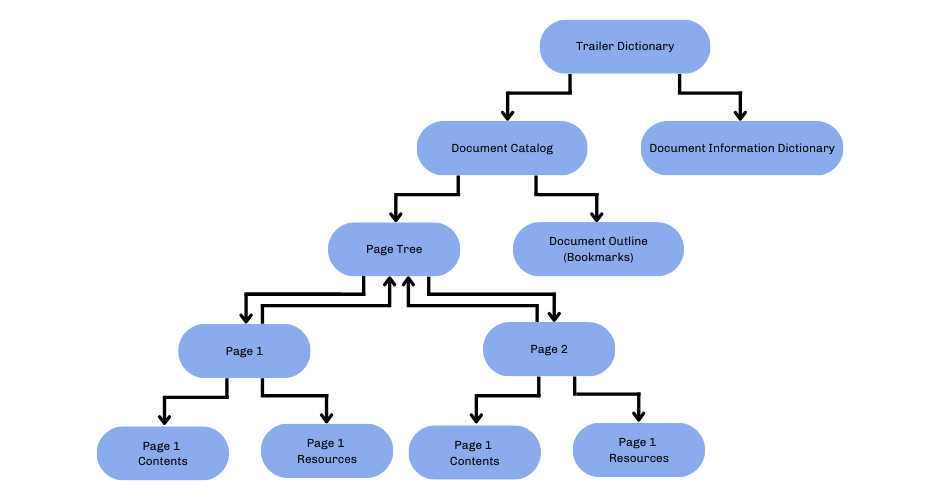
Alt Text: The basic interconnected page-tree structure of a 2-page PDF file
Reference: O’Reilly
Within the body, the objects are organized non-linearly, meaning they aren’t necessarily stored in the order they appear on the page. Instead, each object is indexed, allowing for efficient access and rendering when opening the file. Additionally, the PDF body can contain streams and sequences of bytes used to store large amounts of data, such as the content of an image or a page description in compressed form. This design allows PDFs to efficiently embed and manage vast amounts of data while providing a flexible structure supporting incremental updates. When changes are made to a PDF, rather than rewriting the entire file, new versions of objects can be appended to the end, making saving revisions easier and more efficient.
Linking Data For Efficiency
The cross-reference table (often abbreviated as “xref”) in a PDF is a critical component, serving as the roadmap for locating and accessing the various objects within the document. Given the non-linear organization of the PDF’s body, where objects are often not stored in sequential order, the cross-reference table provides the necessary information to locate each object’s exact position within the file quickly, ensuring that when a PDF reader or editor accesses the file, it can swiftly retrieve and render the content, regardless of the file’s complexity or size.
Each entry in the cross-reference table corresponds to an object in the PDF’s body. The entry specifies the byte offset of the object within the file, effectively pointing to where that object starts. Additionally, each entry can indicate the generation number of the object (helpful in handling incremental updates) and its status, marking whether the object is in use or free. This structure allows for the efficient management and updating of the document, supporting operations like adding, deleting, or modifying content without reorganizing the entire file. In essence, the cross-reference table acts as the backbone of a PDF’s organizational structure, enabling rapid and precise navigation through its content.
Closing Out the File
The trailer in a PDF file is akin to a summary and concluding section that provides the necessary pointers and metadata to assist PDF readers in properly interpreting and navigating the document. Located after the cross-reference table, the trailer offers a snapshot of the file’s essential details and points to critical objects within the document. The trailer consolidates necessary information and pointers, providing a coherent and accurate rendering of the PDF content.
Several crucial entries exist within the trailer. One of the most significant is the Root entry, which points to the catalog object of the PDF, essentially the top-level object that outlines the document’s hierarchical structure. This is pivotal for understanding the organization of content within the file. The Size entry specifies the total number of objects within the PDF, while the Prev entry, if present, points to the location of the previous cross-reference section, a feature especially valuable in incrementally updated PDFs. The trailer also contains an ID entry, an array of two unique identifiers associated with the file’s version and current state. Finally, the trailer holds encryption-related data for encrypted PDFs, ensuring content security and proper access control.
Understanding the Threats
While PDF files are incredibly versatile for document presentation across platforms, this versatility also creates risk. One of the primary risks stems from the embedded script functionality in PDFs. These documents can contain JavaScript or other action-triggered scripts that automatically execute when a user opens the document. Such scripts, if malicious in intent, can initiate unwanted actions, ranging from data extraction to the introduction of malware on the user’s system. Additionally, PDFs can embed various file types, including executable files (.exe). Unsuspecting users might extract and run these embedded files, unwittingly introducing malware to their computers.
Moreover, attackers continually devise methods to exploit vulnerabilities in popular PDF reader software. An outdated reader lacking recent security patches becomes an easy target for such exploits. The ability of PDFs to contain hyperlinks, rich media content, and mimic legitimate documents also presents avenues for threats like phishing attacks or exploitation of media-related vulnerabilities.
Cutting Through the Chaos and Complexity
CDR (Content Disarm and Reconstruction) emerges as a beacon of clarity and security in the complex realm of digital files, especially with complicated formats like PDFs. Instead of delving deep into the nuances of each file and trying to pinpoint every potential threat, CDR adopts a holistic and proactive approach. It works by reconstructing files using only known-safe components. This ensures that even if the original file had embedded threats or unfamiliar components, they get eliminated, leaving behind a sanitized version of the file that retains its core functionality. As only known-safe components are used, CDR protects even files with zero-day or previously unseen threats.
In the broader organizational context, it becomes essential to utilize CDR effectively. To ensure maximum protection, files, especially those crossing the boundaries of an organization, should undergo CDR sanitization. This is because files transferred across different departments, external collaborators, or entering the organization’s network are potential carriers of hidden threats. By implementing CDR as a staple in organizational data transfer processes, companies can significantly reduce the associated risks, ensuring a safer digital environment.
Votiro Makes PDFs Safe
PDFs are a core component of many business operations. Using Votiro, these files can be free from hidden threats. Votiro’s CDR technology eliminates hidden malware and exploits while maintaining the integrity of your content, ensuring nothing valuable gets lost in the sanitization process. With Votiro, you can defend against document-based attacks, file-based vulnerabilities, and even zero-day threats in a wide variety of file formats, generating high-quality reconstruction by rebuilding files with all safe functionality left intact. This ensures that no necessary context or functionality gets lost in the rebuilding process.
Don’t let the complexities of files such as PDFs leave your organization vulnerable to hidden threats. Take proactive measures and partner with Votiro today to fortify your organization against cyber threats and ensure the security of your valuable assets.
Contact us today to learn more about how Votiro raises the bar for preventing hidden threats in files to keep your organization secure while maintaining productivity.



News you can use
Stay up-to-date on the latest industry news and get all the insights you need to navigate the cybersecurity world like a pro. It's as easy as using that form to the right. No catch. Just click, fill, subscribe, and sit back as the information comes to you.
Sign-up Here!
Subscribe to our newsletter for real-time insights about the cybersecurity industry.